Last month, Twitter announced the acquisition of Gnip, one of the main sources for social media data—including Twitter data. In my research I am interested in the politics of platforms and data flows in the social web and in this blog post I would like to explore the role of data intermediaries—Gnip in particular—in regulating access to social media data. I will focus on how Gnip regulates the data flows for social media APIs and how it capitalizes on these data flows. By turning the licensing of API access into an profitable business model the role of these data intermediaries have specific implications for social media research.
The history of Gnip
Gnip launched on July 1st, 2008 as a platform offering access to data from various social media sources. It was founded by Jud Valeski and MyBlogLog founder Eric Marcoullier as “a free centralized callback server that notifies data consumers (such as Plaxo) in real-time when there is new data about their users on various data producing sites (such as Flickr and Digg)” (Feld 2008). Eric Marcoullier’s background in blog service MyBlogLog is of particular interest as Gnip has taken core ideas behind the technical infrastructure of the blogosphere and has repurposed them for the social web.
MyBlogLog
MyBlogLog was a distributed social network for bloggers which allowed them to connect to their blog readers. From 2006-2008 I actively used MyBlogLog. I had a MyBlogLog widget in the sidebar of my blog displaying the names and faces of my blog’s latest visitors. As part of my daily blogging routine I checked out my MyBlogLog readers in the sidebar, visited unknown readers’ profile pages and looked at which other blogs they were reading. It was not only a way to establish a community around your blog, but you could also find out more about your readers and use it as a discovery tool to find new and interesting blogs. In 2007, MyBlogLog was acquired by Yahoo! and six months later founder Eric Marcoullier left Yahoo! while his technical co-founder Todd Sampson stayed on (Feld 2008). In February 2008, MyBlogLog added a new feature to their service which displayed “an activity stream of recent activities by all users on various social networks – blog posts, new photos, bookmarks on Delicious, Facebook updates, Twitter updates, etc.” (Arrington 2008). In doing so, they were no longer only focusing on the activities of other bloggers in the blogosphere but also including their activities on social media platforms and moving into the ‘lifestreaming’ space by aggregating social updates in a central space (Gray 2008). As a service originally focused on bloggers, they were expanding their scope to take the increasing symbiotic relationship between the blogosphere and social media platforms into account (Weltevrede & Helmond, 2012). But in 2010 MyBlogLog came to an end when Yahoo! shut down a number of services including del.icio.us and MyBlogLog (Gannes 2010).
Ping – Gnip
After leaving Yahoo! in 2007, MyBlogLog-founder Eric Marcoullier started working on a new idea which would eventually become Gnip. In two blog posts by Brad Feld from Foundry Group–an early Gnip investor–Feld provides insights into the ideas behind Gnip and its name. Gnip is ‘ping’ spelled backwards and Feld recounts how Marcoullier was “originally calling the idea Pingery but somewhere along the way Gnip popped out and it stuck (“meta-ping server” was a little awkward)” (Feld 2008). Ping is a central technique in the blogosphere that allows (blog) search engines and other aggregators to know when a blog has been updated. This notification system is built into blog software so that when you publish a new blog post, it automatically sends out a ping (a XML-RPC signal) that notifies a number of ping services that your blog has been updated. Search engines then poll these services to detect blog updates so that they can index these new blog posts. This means that search engines don’t have poll the millions or billions of blogs out there for updates but that they only have to poll these central ping services. Ping solved a scalability issue of update notifications in the blogosphere because polling a very large number of blogs on a very frequent basis is impossible. Ping servers established themselves as “the backbone of the blogosphere infrastructure and are a crucially important piece of the real-time web” (Arrington 2005). In my MA thesis on the symbiotic relationship between blog software and search engines I describe how ping servers form an essential part of the blogosphere’s infrastructure because they act as centralizing forces in the distributed network of blogs that notify subscriber, aggregators and search engines of new content (Helmond 2008, 70). Blog aggregators and blog search engines could get fresh content from updated blogs by polling central ping servers instead of individual blogs.
APIs as the glue of the social web
Gnip sought to solve a scalability issue of the social web—third parties constantly polling social media platform APIs for new data— in a similar manner by becoming a central point for new content from social media platforms offering access to their data. Traditionally, social media platforms have offered (partial) access to their data to outsiders by using APIs, application programming interfaces. APIs can be seen as the industry-preferred method to gain access to platform data—in contrast to screen scraping as an early method to repurpose social media data (Helmond & Sandvig, 2010). Social media platforms can regulate data access through their APIs, for example by limiting which data is available and how much of it can be requested and by whom. APIs allow external developers to build new applications on top of social media platforms and they have enabled the development of an ecosystem of services and apps that make use of social media platform data and functionality (see also Bucher 2013). Think for example of Tinder, the dating app, which is built on top of the Facebook platform. When you install Tinder you have to log in with your Facebook account, after which the dating app finds matches based on proximity but also on shared Facebook friends and shared Facebook likes. Another example of how APIs are used is the practice of sharing content across various social media platforms using social buttons (Helmond 2013). APIs can be seen as the glue of the social web, connecting social media platforms and creating a social media ecosystem.
APIs overload
But the birth of this new “ecosystem of connective media” (van Dijck 2013) and its reliance on APIs (Langlois et. al 2009) came with technical growing pains:
Web services that became popular overnight had performance issues, especially when their APIs were getting hammered. The solution for some was to simply turn off specific services when the load got high, or throttle (limit) the number of API calls in a certain time period from each individual IP address (Feld 2008).
With the increasing number of third-party applications constantly requesting data, some platforms started to limit access or completely shut down API access. This did not only have implications for developers building apps on top of platforms but also for the users of these platforms. Twitter implemented a daily limit of 70 requests per hour which also affected users. If you exceeded the 70 requests per hour—which also included tweeting, replying or retweeting—you simply were simply cut off. Actively live tweeting an event could easily exceed the imposed limit. In the words of Nate Tkacz, commenting on another user being barred from posting during a conference: “in this world, to be prolific, is to be a spammer.”
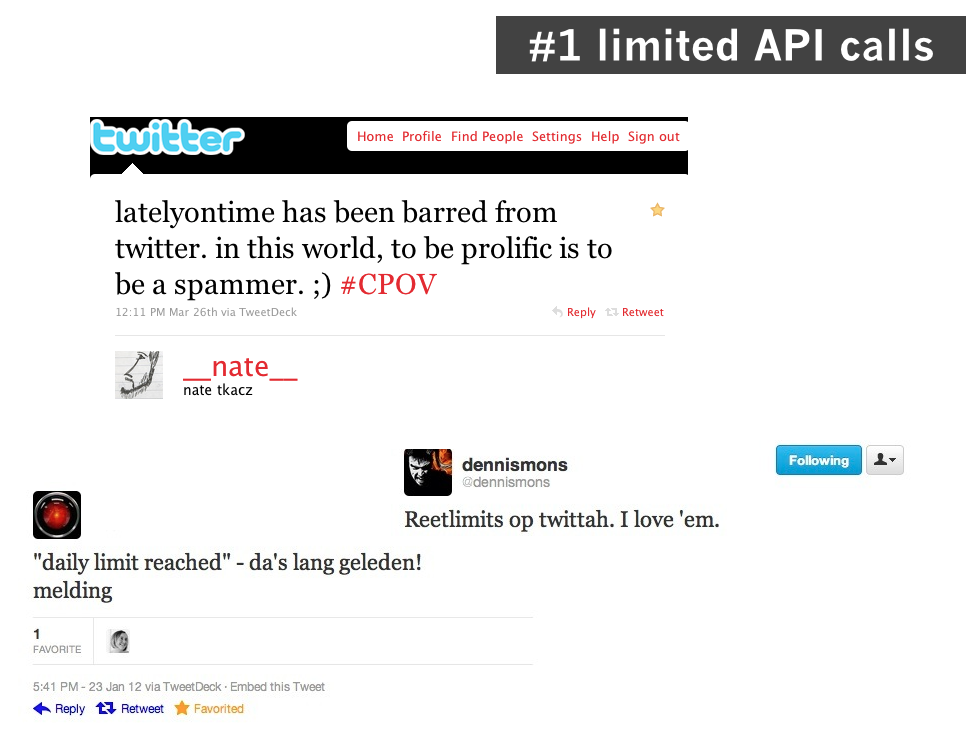
However, limiting the number of API calls, or shutting down API access did not fix the actual problem and affected users too. Gnip was created to address the issue of third-parties constantly polling social media platform APIs for new data by bringing these different APIs together into one system (Feld 2008). Similar to central ping services in the blogosphere Gnip would become the central service to call social media APIs and to poll for new data: “Gnip plans to sit in the middle of this and transform all of these interactions back to many-to-one where there are many web services talking to one centralized service – Gnip” (Feld 2008). Instead of thousands of applications frequently calling individual social media platform APIs, they could now call a single API, the Gnip API thereby leveraging the API load for these platforms. Since its inception Gnip has acted as an intermediary of social data and it was specifically designed “to sit in between social networks and other web services that produce a lot of user content and data (like Digg, Delicious, Flickr, etc.) and data consumers (like Plaxo, SocialThing, MyBlogLog, etc.) with the express goal of reducing API load and making the services more efficient†(Arrington 2008). In a blogpost on Techcrunch, covering the launch of Gnip, author Nik Cubrilovic explains in detail how Gnip functions as “a web services proxy to enable consuming services to easily access user data from a variety of sources:”
A publisher can either push data to Gnip using their API’s, or Gnip can poll the latest user data. For consumers, Gnip offers a standards-based API to access all the data across the different publishers. A key advantage of Gnip is that new events are pushed to the consumer, rather than relying on the consuming application to poll the publishers multiple times as a way of finding new events. For example, instead of polling Digg every few seconds for a new event for a particular user, Gnip can ping the consuming service – saving multiple round-trip API requests and resolving a large-scale problem that exists with current web services infrastructure. With a ping-based notification mechanism for new events via Gnip the publisher can be spared the load of multiple polling requests from multiple consuming applications (Cubrilovic 2008).
Gnip launched as a central service offering access to a great number of popular APIs from platforms including Digg, Flickr, del.icio.us, MyBlogLog, Six Apart and more. At launch, technology blog ReadWrite described the new service as “the grand central station and universal translation service for the new social web†(Kirkpatrick 2008).
Gnip’s business model as data proxy
Gnip regulates the data flows between various social media platforms and social media data consumers by licensing access to these data flows. In September 2008, a few months after the initial launch, Gnip launched it’s “2.0” version which no longer required data consumers to poll for new data with Gnip, but instead, new data would be pushed to them in real-time (Arrington 2008). While Gnip initially launched as a free service, the new version also came with a freemium business model:
Gnip’s business model is freemium – lots of data for free and commercial data consumers pay when they go over certain thresholds (non commercial use is free). The model is based on the number of users and the number of filters tracked. Basically, any time a service is tracking more than 10,000 people and/or rules for a certain data provider, they’ll start paying at a rate of $0.01 per user or rule per month, with a maximum payment of $1,000 per month for each data provider tracked (Arrington 2008).
Gnip connects to various social media platform APIs and then licenses access to this data through the single Gnip API. In doing so Gnip has turned data reselling—besides advertising—into a profitable business model for the social web, not only for Gnip itself but also for social media platforms that make use of Gnip. I will continue by briefly discussing Gnip and Twitter’s relationship before discussing the implications of this emerging business model for social media researchers.
Gnip and Twitter
Gnip and Twitter’s relationship goes back to 2008 when Twitter decided to open up its data stream by giving Gnip access to the Twitter XMPP “firehose” which sent out all of Twitter’s data in a realtime data stream (Arrington 2008). At Gnip’s launch Twitter was not part of the group of platforms offering access to their data. A week after the launch Eric Marcoullier explained “That Twitter Thing” to its users—who were asking for Twitter data—by explaining that Gnip was still waiting for access to Twitter’s data and by outlining how Twitter could benefit from doing so. Only a week later Twitter gave Gnip access to their resource-intensive XMPP “firehose” thereby shifting the infrastructural load, that it was suffering from, to Gnip. With this data access deal Gnip and Twitter became unofficial partners. On October 2008 Twitter outlined the different ways to get data into and out of Twitter for developers and hinted at giving Gnip access to its full data, including meta-data, which until then had been on an experimental basis. It wasn’t until 2010 that their partnership with experimental perks became official.
In 2010 Gnip became Twitter’s first authorized data reseller offering access to “the Halfhose (50 percent of Tweets at a cost of $30,000 per month), the Decahose (10 percent of Tweets for $5,000 per month) and the Mentionhose (all mentions of a user including @replies and re-Tweets for $20,000 per month)” (Gannes 2010). Notably absent is the so-called ‘firehose,’ the real-time stream of all tweets. Twitter previously sold access to the firehose to Google ($15 million) and Microsoft ($10 million) in 2009. Before the official partnership announcement with Gnip, Twitter’s pricing model for granting access to data had been rather arbitrary since ““Twitter is focused on creating consumer products and we’re not built to license data,†Williams said, adding, “Twitter has always invested in the ecosystem and startups and we believe that a lot of innovation can happen on top of the data. Pricing and terms definitely vary by where you are from a corporate perspective— (Gannes 2010). In this interview Evan Williams states that Twitter was never built for licensing data, which may be a reason they entered into a relationship with Gnip in the first place. In contrast to Twitter, Gnip’s infrastructure was built to regulate API traffic which at the same time enables the monetization of licensing access to the data available through APIs. This became even clearer in August 2012 when Twitter announced a new version of its API which came with a new and stricter rate limiting (Sippey 2012). The new restrictions imposed through the Twitter API version 1.1 meant that developers could request less data which affected third-party clients for Twitter (Warren 2012).
Two weeks later Twitter launched its “Certified Products Program†which focused on three product categories: engagement, analytics and data resellers—including Gnip (Lardinois 2012). With the introduction of Certified Products shortly after the new API restrictions, Twitter made clear that large scale access to Twitter data had to be bought. In a blog post addressing the changes in the new Twitter API v1.1, Gnip’s product manager Adam Torres calculates that the new restrictions come down to 80% less data (Tornes 2013). In the same post he also promotes Gnip as the paid-for solution:
Combined with the existing limits to the number of results returned per request, it will be much more difficult to consume the volume or levels of data coverage you could previously through the Twitter API. If the new rate limit is an issue, you can get full coverage commercial grade Twitter access through Gnip which isn’t subject to rate limits (Tornes 2013).
In February 2012 Gnip announced that it would become the first authorized reseller of “historical” (the past 30 days) for Twitter data. This marked another important moment in Gnip and Twitter’s business relationship, followed by the announcement of Gnip offering full access to historical Twitter data in October.
Twitter’s business model: Advertising & data licensing
The new API and the Certified Products Program point towards a shift in Twitter’s business model by introducing intermediaries such as analytics companies and data resellers for access to large scale Twitter data.
Despite Williams’ statement that Twitter wasn’t built for licensing data, it had previously been making a bit of money by selling access to its firehose as previously described. However, the main source of income for Twitter has always come from selling advertisements: “Twitter is an advertising business, and ads make up nearly 90% of the company’s revenue.” (Edwards 2014). While Twitter’s current business model relies on advertising, data licensing as a source of income is growing steadily: “In 2013, Twitter got $70 million in data licensing payments, up 48% from the year before” (Edwards 2014).
Using social media data for research
If we are moving towards the licensing of API access as a business model, then what does this mean for researchers working with social media data? Gnip is only one of the four data intermediaries—together with DataSift, Dataminr and Topsy (now owned by Apple, an indicator of big players buying up the middleman market of data)—offering access to Twitter’s firehose. Additionally, Gnip (now owned by Twitter) and Topsy (now owned by Apple) also offer access to the historical archive of all tweets. What are the consequences of intermediaries for researchers working with Twitter data? boyd & Crawford (2011) and Bruns & Stieglitz (2013) have previously addressed the issues that researchers are facing when working with APIs. With the introduction of data intermediaries data access has become increasingly hard to come by since ‘full’ access is often no longer available from the original source (the social media platform) but only through intermediaries at a hefty price.
Two months before the acquisition of Gnip by Twitter they announced a partnership in a new Data Grants program that would give a small selection of academic researchers access to all Twitter data. However, by applying for the grants program you had to accept their “Data Grant Submission Agreement v1.0.” Researcher Eszter Hargittai critically investigated the conditions of getting access to data for research and raised some important questions about the relationship between Twitter and researchers in her blog post ‘Wait, so what do you still own?‘
Even if we gain access to an expensive resource such as Gnip, the intermediaries also point to a further obfuscation of the data we are working with. The application programming interface (API), as the name already indicates, provides an interface to the data which explicates that we are always “interfacing” with the data and that we never have access to the “raw” data. In “Raw Data is an Oxymoron” edited by Lisa Gitelman, Bowker reminds us that data is never “raw†but always “cooked†(2013, p. 2). Social media intermediaries play an important role in “cooking” data. Gnip “cooks” its data by “Adding the Bling” referring to the addition of extra metadata to Twitter data. These so-called “Enrichments” include geo-data enrichments which “adds a new kind of Twitter geodata from what may be natively available from social sources.” In other words, Twitter data is enriched with data from other sources such as Foursquare logins.
For researchers, working with social media data intermediaries also requires new skills and new ways of thinking through data by seeing social media data as relational. Social media data are not only aggregated and combined but also instantly cooked through the addition of “bling.”
Acknowledgements
I would like to thank the Social Media Collective and visiting researchers for providing feedback on my initial thoughts behind this blogpost during my visit from April 14-18 at Microsoft Research New England. Thank you Kate Crawford, Nancy Baym, Mary Gray, Kate Miltner, Tarleton Gillespie, Megan Finn, Jonathan Sterne, Li Cornfeld as well as my colleague Thomas Poell from the University of Amsterdam.
2 thoughts on “Adding the bling: The role of social media data intermediaries”